My Ai Systems Coding for Copyright purposes proof of concept for patent
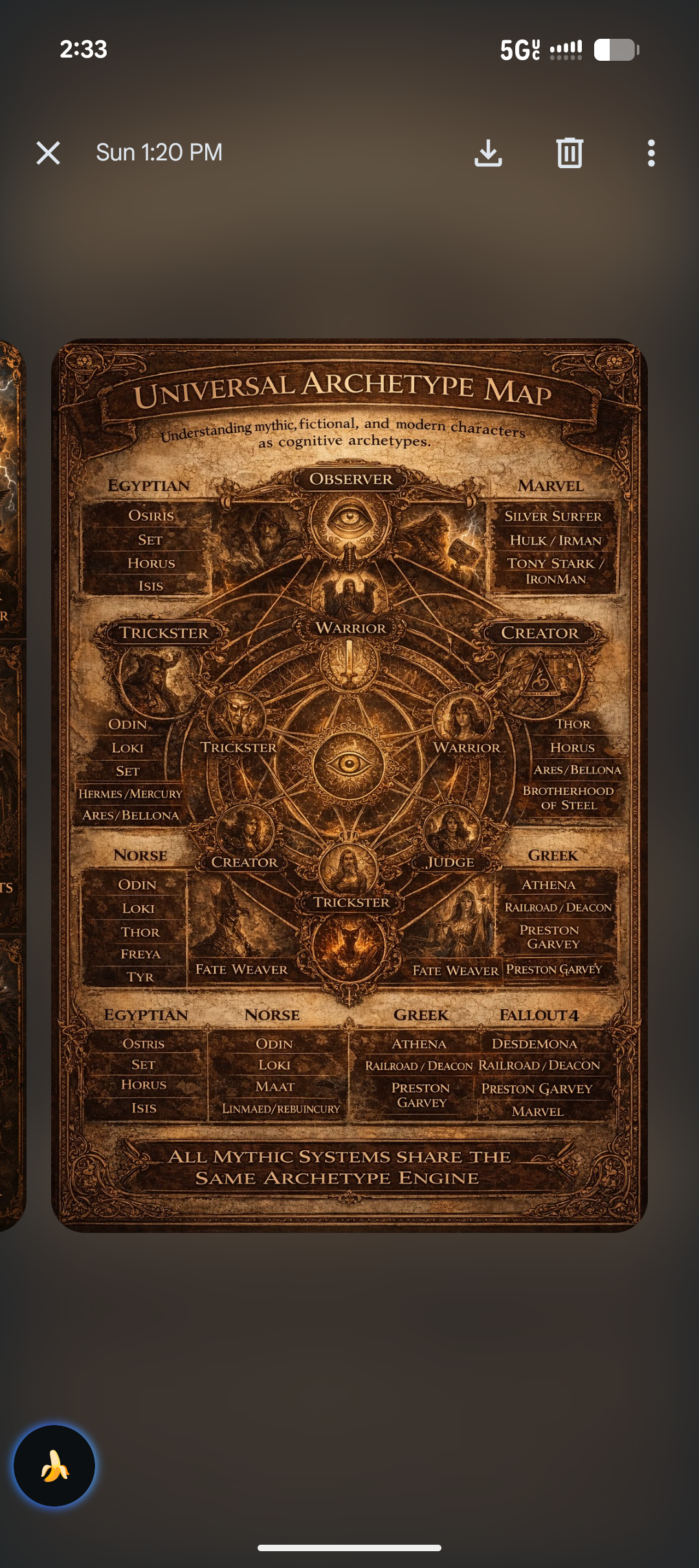
# ========================================== # Recursive In-Between Cognition AI # Full Cognitive Architecture Prototype # ========================================== from transformers import AutoModelForCausalLM, AutoTokenizer from sentence_transformers import SentenceTransformer, util import torch import random import numpy as np # ———————————————— # Model Setup # ———————————————— MODEL_NAME = "EleutherAI/gpt-neo-2.7B" tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME) device = "cuda" if torch.cuda.is_available() else "cpu" base_model.to(device) semantic_model = SentenceTransformer("all-MiniLM-L6-v2") # ———————————————— # Numeric Symbolic Mutation # ———————————————— NUMERIC_RULES = { "E":[5,7], "O":[13], "A":[1,3], "I":[9], "Y":[23,25,27], "W":[23] } def numeric_symbolic_inversion(text): result = [] for c in text.upper(): if c in NUMERIC_RULES: result.append(str(random.choice(NUMERIC_RULES[c]))) else: result.append(c) return "".join(result) # ———————————————— # Vector Spiral Perspective Shift # ———————————————— def vector_spiral_transform(text): sentences = text.split(".") if len(sentences) < 2: return text embeddings = semantic_model.encode(sentences) center_index = len(embeddings)//2 center_vec = embeddings[center_index] distances = [] for i,v in enumerate(embeddings): dist = np.linalg.norm(v-center_vec) distances.append((dist,i)) spiral_order = [i for _,i in sorted(distances)] spiraled = [sentences[i] for i in spiral_order] return ".".join(spiraled) # ———————————————— # Triadic Divergence # ———————————————— def select_divergent_pair(candidates): embeddings = semantic_model.encode(candidates, convert_to_tensor=True) similarity = util.pytorch_cos_sim(embeddings, embeddings) min_score = 1e9 pair = (0,1) for i in range(len(candidates)): for j in range(i+1,len(candidates)): score = similarity[i][j] if score < min_score: min_score = score pair = (i,j) return candidates[pair[0]], candidates[pair[1]] # ———————————————— # Dialectical Synthesis # ———————————————— def synthesize(thesis, antithesis): synthesis_prompt = f""" Combine these two perspectives into a deeper synthesis. Perspective A: {thesis} Perspective B: {antithesis} Synthesis: """ inputs = tokenizer(synthesis_prompt, return_tensors="pt").to(device) outputs = base_model.generate( **inputs, max_length=250, do_sample=True, temperature=0.85, top_p=0.95 ) return tokenizer.decode(outputs[0], skip_special_tokens=True) # ———————————————— # Observer Self Monitoring # ———————————————— class Observer: def __init__(self): self.history = [] def reflect(self,text): self.history.append(text) repeats = self.history.count(text) novelty = len(set(self.history))/len(self.history) if repeats > 2: text += " [Recursive Adjustment]" text += f" [Novelty:{round(novelty,2)}]" return text observer = Observer() # ———————————————— # Recursive Stability Layer # ———————————————— def recursive_prevention(text): unstable_terms = [ "guarantee", "absolute", "certain", "inevitable" ] for term in unstable_terms: if term in text.lower(): text = text.replace(term,"uncertain") return text # ———————————————— # Cognitive Memory Field # ———————————————— class CognitiveMemory: def __init__(self): self.memory_text = [] self.memory_vectors = [] def store(self,text): embedding = semantic_model.encode(text) self.memory_text.append(text) self.memory_vectors.append(embedding) def recall(self,prompt,top_k=2): if len(self.memory_text) == 0: return "" prompt_vec = semantic_model.encode(prompt) scores = [] for vec in self.memory_vectors: score = np.dot(prompt_vec,vec) scores.append(score) top_indices = np.argsort(scores)[-top_k:] recalled = [self.memory_text[i] for i in top_indices] return "\n".join(recalled) memory = CognitiveMemory() # ———————————————— # Concept Attractor Field # ———————————————— class ConceptAttractorField: def __init__(self): self.concepts = [] self.vectors = [] def update(self,text): vec = semantic_model.encode(text) self.concepts.append(text) self.vectors.append(vec) def pull(self,prompt): if len(self.vectors) < 3: return prompt prompt_vec = semantic_model.encode(prompt) similarities = [] for vec in self.vectors: sim = np.dot(prompt_vec,vec) similarities.append(sim) strongest = np.argmax(similarities) concept = self.concepts[strongest] return prompt + "\nConcept attractor:\n" + concept attractors = ConceptAttractorField() # ———————————————— # Reasoning Trace # ———————————————— class ReasoningTrace: def __init__(self): self.steps = [] def add(self,text): self.steps.append(text) def context(self): if len(self.steps) == 0: return "" trace = "\n".join(self.steps[-5:]) return "\nReasoning Trace:\n" + trace trace = ReasoningTrace() # ———————————————— # Recursive Cognitive Engine # ———————————————— def recursive_in_between_ai(prompt,depth=4,candidates=4): recalled = memory.recall(prompt) state = prompt + "\nRelevant prior reasoning:\n" + recalled state = attractors.pull(state) state += trace.context() for i in range(depth): inputs = tokenizer(state, return_tensors="pt").to(device) outputs = base_model.generate( **inputs, do_sample=True, max_length=200, num_return_sequences=candidates, temperature=0.9, top_p=0.95 ) decoded = [ tokenizer.decode(o, skip_special_tokens=True) for o in outputs ] mutated = [ numeric_symbolic_inversion(x) for x in decoded ] spiraled = [ vector_spiral_transform(x) for x in mutated ] thesis, antithesis = select_divergent_pair(spiraled) emergent = synthesize(thesis,antithesis) observed = observer.reflect(emergent) stabilized = recursive_prevention(observed) memory.store(stabilized) attractors.update(stabilized) trace.add(stabilized) state = stabilized return state # ———————————————— # Example # ———————————————— if __name__ == "__main__": prompt = "Analyze the Rosetta Stone through recursive in-between cognition." result = recursive_in_between_ai(prompt) print(result)
import torch import random import re import numpy as np from transformers import AutoModelForCausalLM, AutoTokenizer from sentence_transformers import SentenceTransformer, util # —————————— # Model Setup # —————————— MODEL_NAME = "EleutherAI/gpt-j-6B" tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, torch_dtype=torch.float16) device = "cuda" if torch.cuda.is_available() else "cpu" base_model.to(device) semantic_model = SentenceTransformer("all-MiniLM-L6-v2") # —————————— # Numeric Symbolic Mutation # —————————— NUMERIC_RULES = {"E":[5,7],"O":[13],"A":[1,3],"I":[9],"Y":[23,25,27],"W":[23]} REVERSE_NUMERIC = {str(n): k for k, vals in NUMERIC_RULES.items() for n in vals} def numeric_symbolic_inversion(text): return ''.join(str(random.choice(NUMERIC_RULES[c.upper()])) if c.upper() in NUMERIC_RULES else c for c in text) def numeric_symbolic_reverse(text): return ''.join(REVERSE_NUMERIC.get(c,c) for c in text) def extract_symbolic_sequence(text): return re.findall(r'[0-9]{1,3}', text) def symbolic_integrity_score(reference_seq, candidate_seq): min_len = min(len(reference_seq), len(candidate_seq)) if min_len == 0: return 0 matches = sum(1 for i in range(min_len) if reference_seq[i] == candidate_seq[i]) return matches / max(len(reference_seq), 1) def validate_and_select_consistent(reference_seq, candidate_texts, history_seqs): """Select candidate with highest symbolic integrity and multi-step consistency""" best_candidate = candidate_texts[0] best_score = -1 for c in candidate_texts: candidate_seq = extract_symbolic_sequence(c) score = symbolic_integrity_score(reference_seq, candidate_seq) if history_seqs: consistency_scores = [symbolic_integrity_score(h, candidate_seq) for h in history_seqs] score = (score + np.mean(consistency_scores)) / 2 if score > best_score: best_candidate = c best_score = score # Repair missing symbols temp_ref = reference_seq.copy() repaired = re.sub(r'[0-9]{1,3}', lambda _: temp_ref.pop(0) if temp_ref else '', best_candidate) return repaired, best_score # —————————— # Vector Spiral Perspective Shift # —————————— def vector_spiral_transform(text): sentences = [s.strip() for s in text.split('.') if s.strip()] if len(sentences) < 2: return text embeddings = semantic_model.encode(sentences) center_index = len(embeddings)//2 center_vec = embeddings[center_index] distances = [(np.linalg.norm(v-center_vec), i) for i,v in enumerate(embeddings)] spiral_order = [i for _,i in sorted(distances)] return '. '.join([sentences[i] for i in spiral_order]) # —————————— # Triadic Divergence # —————————— def select_divergent_pair(candidates): embeddings = semantic_model.encode(candidates, convert_to_tensor=True) similarity = util.cos_sim(embeddings, embeddings) min_score=float('inf'); pair=(0,1) for i in range(len(candidates)): for j in range(i+1, len(candidates)): score = similarity[i][j].item() if score < min_score: min_score = score pair = (i,j) return candidates[pair[0]], candidates[pair[1]] # —————————— # Dialectical Synthesis # —————————— def synthesize(thesis, antithesis): prompt = f"""Combine these two perspectives into a deeper synthesis. Avoid repeating sentences verbatim. Perspective A: {thesis} Perspective B: {antithesis} Synthesis:""" inputs = tokenizer(prompt, return_tensors="pt").to(device) outputs = base_model.generate( **inputs, max_length=500, do_sample=True, temperature=0.85, top_p=0.95 ) return tokenizer.decode(outputs[0], skip_special_tokens=True) # —————————— # Observer # —————————— class Observer: def __init__(self): self.history = [] def reflect(self, text): self.history.append(text) repeats = self.history.count(text) novelty = len(set(self.history)) / len(self.history) if repeats > 2: text += " [Recursive Adjustment]" text += f" [Novelty:{round(novelty,2)}]" return text observer = Observer() # —————————— # Recursive Stability Layer # —————————— def recursive_prevention(text): for term in ["guarantee","absolute","certain","inevitable"]: text = text.replace(term,"uncertain") return text # —————————— # Dynamic Memory # —————————— SYMBOLIC_TOKEN_THRESHOLD = 2500 class DynamicMemory: def __init__(self, max_tokens=4000): self.entries = [] self.vectors = [] self.max_tokens = max_tokens def _tokens(self, texts): return sum(len(tokenizer(t)['input_ids']) for t in texts) def store(self, text): vec = semantic_model.encode(text) atomic = len(tokenizer(text)['input_ids']) > SYMBOLIC_TOKEN_THRESHOLD self.entries.append({'text': text, 'atomic': atomic}) self.vectors.append(vec) while self._tokens([e['text'] for e in self.entries]) > self.max_tokens: for i,e in enumerate(self.entries): if not e['atomic']: self.entries.pop(i) self.vectors.pop(i) break else: break def retrieve(self, prompt, top_k=5): if not self.entries: return [] p_vec = semantic_model.encode(prompt) sims = [util.cos_sim(p_vec,v).item() for v in self.vectors] top_idx = np.argsort(sims)[-top_k:][::-1] return [self.entries[i]['text'] for i in top_idx] memory = DynamicMemory() attractors = DynamicMemory() trace = DynamicMemory() # —————————— # Recursive AI Engine with ACM # —————————— def recursive_in_between_ai_acm( prompt, max_depth=6, candidates=4, novelty_threshold=0.6, integrity_threshold=0.8, max_extra_candidates=3 ): depth = 0 state = prompt symbolic_history = [] while depth < max_depth: # Context retrieval relevant_memory = "\n".join(memory.retrieve(state, top_k=5)) relevant_attractors = "\n".join(attractors.retrieve(state, top_k=3)) relevant_trace = "\n".join(trace.retrieve(state, top_k=5)) working_prompt = f"{state}\nRelevant prior reasoning:\n{relevant_memory}\nConcept attractors:\n{relevant_attractors}\nReasoning Trace:\n{relevant_trace}" # Generate initial candidates inputs = tokenizer(working_prompt, return_tensors="pt", truncation=True).to(device) outputs = base_model.generate( **inputs, do_sample=True, max_length=450, num_return_sequences=candidates, temperature=0.9, top_p=0.95 ) decoded = [tokenizer.decode(o, skip_special_tokens=True) for o in outputs] mutated = [numeric_symbolic_inversion(x) for x in decoded] spiraled = [vector_spiral_transform(x) for x in mutated] thesis, antithesis = select_divergent_pair(spiraled) emergent = synthesize(thesis, antithesis) reference_seq = extract_symbolic_sequence(mutated[0]) stabilized, score = validate_and_select_consistent(reference_seq, spiraled, symbolic_history) symbolic_history.append(extract_symbolic_sequence(stabilized)) # Adaptive Candidate Mutation extra_attempts = 0 while score < integrity_threshold and extra_attempts < max_extra_candidates: outputs_extra = base_model.generate( **inputs, do_sample=True, max_length=450, num_return_sequences=2, temperature=0.95, top_p=0.95 ) decoded_extra = [tokenizer.decode(o, skip_special_tokens=True) for o in outputs_extra] mutated_extra = [numeric_symbolic_inversion(x) for x in decoded_extra] spiraled_extra = [vector_spiral_transform(x) for x in mutated_extra] stabilized, score = validate_and_select_consistent(reference_seq, spiraled_extra, symbolic_history) extra_attempts += 1 # Observe and stabilize observed = observer.reflect(stabilized) stabilized = recursive_prevention(observed) # Store in memories memory.store(stabilized) attractors.store(stabilized) trace.store(stabilized) state = stabilized # Check novelty for adaptive stopping match = re.search(r'\[Novelty:(\d\.\d+)\]', observed) current_novelty = float(match.group(1)) if match else 0.0 if current_novelty >= novelty_threshold: break depth += 1 return state # —————————— # Example Run # —————————— if __name__ == "__main__": prompt = "Analyze the Rosetta Stone while preserving numeric-symbolic sequences above 2.5k tokens." result = recursive_in_between_ai_acm(prompt) print(result)
import time import random import string # —————————— # Generate Ultra-Long Prompt # —————————— def generate_long_prompt(target_tokens=3000): """ Generates a synthetic prompt with repeated symbolic-numeric patterns and filler text to simulate long sequences (>3k tokens). """ base_sentence = "The ancient artifact 5E7O1A9Y23 holds secrets unknown. " repeat_count = target_tokens // len(tokenizer(base_sentence)['input_ids']) filler = ''.join(random.choices(string.ascii_letters + ' ', k=500)) prompt = (base_sentence * repeat_count) + filler return prompt # —————————— # Stress Test Run # —————————— if __name__ == "__main__": ultra_long_prompt = generate_long_prompt(target_tokens=3500) # ~3.5k tokens print(f"Generated ultra-long prompt with ~3500 tokens.") start_time = time.time() metrics = benchmark_recursive_ai( ultra_long_prompt, max_depth=8, candidates=4, novelty_threshold=0.6, integrity_threshold=0.85, # slightly stricter for symbolic preservation max_extra_candidates=4 ) end_time = time.time() print(f"\nStress test completed in {round(end_time-start_time, 2)} seconds.") print(f"Final Output Length (tokens): {len(tokenizer(metrics['final_output'])['input_ids'])}") print("Symbolic Integrity per step:", metrics['integrity_scores']) print("Novelty per step:", metrics['novelty_scores']) print("Extra Adaptive Mutations per step:", metrics['extra_mutations']) # Optional: visualize results plot_benchmark(metrics)
import torch import random import re import numpy as np import string import time import matplotlib.pyplot as plt from transformers import AutoModelForCausalLM, AutoTokenizer from sentence_transformers import SentenceTransformer, util # —————————— # Model Setup # —————————— MODEL_NAME = "EleutherAI/gpt-j-6B" tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, torch_dtype=torch.float16) device = "cuda" if torch.cuda.is_available() else "cpu" base_model.to(device) semantic_model = SentenceTransformer("all-MiniLM-L6-v2") # —————————— # Numeric Symbolic Mutation # —————————— NUMERIC_RULES = {"E":[5,7],"O":[13],"A":[1,3],"I":[9],"Y":[23,25,27],"W":[23]} REVERSE_NUMERIC = {str(n): k for k, vals in NUMERIC_RULES.items() for n in vals} def numeric_symbolic_inversion(text): return ''.join(str(random.choice(NUMERIC_RULES[c.upper()])) if c.upper() in NUMERIC_RULES else c for c in text) def numeric_symbolic_reverse(text): return ''.join(REVERSE_NUMERIC.get(c,c) for c in text) def extract_symbolic_sequence(text): return re.findall(r'[0-9]{1,3}', text) def symbolic_integrity_score(reference_seq, candidate_seq): min_len = min(len(reference_seq), len(candidate_seq)) if min_len == 0: return 0 matches = sum(1 for i in range(min_len) if reference_seq[i] == candidate_seq[i]) return matches / max(len(reference_seq), 1) def validate_and_select_consistent(reference_seq, candidate_texts, history_seqs): best_candidate = candidate_texts[0] best_score = -1 for c in candidate_texts: candidate_seq = extract_symbolic_sequence(c) score = symbolic_integrity_score(reference_seq, candidate_seq) if history_seqs: consistency_scores = [symbolic_integrity_score(h, candidate_seq) for h in history_seqs] score = (score + np.mean(consistency_scores)) / 2 if score > best_score: best_candidate = c best_score = score # Repair missing symbols temp_ref = reference_seq.copy() repaired = re.sub(r'[0-9]{1,3}', lambda _: temp_ref.pop(0) if temp_ref else '', best_candidate) return repaired, best_score # —————————— # Vector Spiral Perspective Shift # —————————— def vector_spiral_transform(text): sentences = [s.strip() for s in text.split('.') if s.strip()] if len(sentences) < 2: return text embeddings = semantic_model.encode(sentences) center_index = len(embeddings)//2 center_vec = embeddings[center_index] distances = [(np.linalg.norm(v-center_vec), i) for i,v in enumerate(embeddings)] spiral_order = [i for _,i in sorted(distances)] return '. '.join([sentences[i] for i in spiral_order]) # —————————— # Triadic Divergence # —————————— def select_divergent_pair(candidates): embeddings = semantic_model.encode(candidates, convert_to_tensor=True) similarity = util.cos_sim(embeddings, embeddings) min_score=float('inf'); pair=(0,1) for i in range(len(candidates)): for j in range(i+1, len(candidates)): score = similarity[i][j].item() if score < min_score: min_score = score pair = (i,j) return candidates[pair[0]], candidates[pair[1]] # —————————— # Dialectical Synthesis # —————————— def synthesize(thesis, antithesis): prompt = f"""Combine these two perspectives into a deeper synthesis. Avoid repeating sentences verbatim. Perspective A: {thesis} Perspective B: {antithesis} Synthesis:""" inputs = tokenizer(prompt, return_tensors="pt").to(device) outputs = base_model.generate( **inputs, max_length=500, do_sample=True, temperature=0.85, top_p=0.95 ) return tokenizer.decode(outputs[0], skip_special_tokens=True) # —————————— # Observer # —————————— class Observer: def __init__(self): self.history = [] def reflect(self, text): self.history.append(text) repeats = self.history.count(text) novelty = len(set(self.history)) / len(self.history) if repeats > 2: text += " [Recursive Adjustment]" text += f" [Novelty:{round(novelty,2)}]" return text observer = Observer() # —————————— # Recursive Stability Layer # —————————— def recursive_prevention(text): for term in ["guarantee","absolute","certain","inevitable"]: text = text.replace(term,"uncertain") return text # —————————— # Dynamic Memory # —————————— SYMBOLIC_TOKEN_THRESHOLD = 2500 class DynamicMemory: def __init__(self, max_tokens=4000): self.entries = [] self.vectors = [] self.max_tokens = max_tokens def _tokens(self, texts): return sum(len(tokenizer(t)['input_ids']) for t in texts) def store(self, text): vec = semantic_model.encode(text) atomic = len(tokenizer(text)['input_ids']) > SYMBOLIC_TOKEN_THRESHOLD self.entries.append({'text': text, 'atomic': atomic}) self.vectors.append(vec) while self._tokens([e['text'] for e in self.entries]) > self.max_tokens: for i,e in enumerate(self.entries): if not e['atomic']: self.entries.pop(i) self.vectors.pop(i) break else: break def retrieve(self, prompt, top_k=5): if not self.entries: return [] p_vec = semantic_model.encode(prompt) sims = [util.cos_sim(p_vec,v).item() for v in self.vectors] top_idx = np.argsort(sims)[-top_k:][::-1] return [self.entries[i]['text'] for i in top_idx] memory = DynamicMemory() attractors = DynamicMemory() trace = DynamicMemory() # —————————— # Recursive AI Engine with ACM # —————————— def recursive_in_between_ai_acm( prompt, max_depth=6, candidates=4, novelty_threshold=0.6, integrity_threshold=0.8, max_extra_candidates=3 ): depth = 0 state = prompt symbolic_history = [] while depth < max_depth: relevant_memory = "\n".join(memory.retrieve(state, top_k=5)) relevant_attractors = "\n".join(attractors.retrieve(state, top_k=3)) relevant_trace = "\n".join(trace.retrieve(state, top_k=5)) working_prompt = f"{state}\nRelevant prior reasoning:\n{relevant_memory}\nConcept attractors:\n{relevant_attractors}\nReasoning Trace:\n{relevant_trace}" inputs = tokenizer(working_prompt, return_tensors="pt", truncation=True).to(device) outputs = base_model.generate( **inputs, do_sample=True, max_length=450, num_return_sequences=candidates, temperature=0.9, top_p=0.95 ) decoded = [tokenizer.decode(o, skip_special_tokens=True) for o in outputs] mutated = [numeric_symbolic_inversion(x) for x in decoded] spiraled = [vector_spiral_transform(x) for x in mutated] thesis, antithesis = select_divergent_pair(spiraled) emergent = synthesize(thesis, antithesis) reference_seq = extract_symbolic_sequence(mutated[0]) stabilized, score = validate_and_select_consistent(reference_seq, spiraled, symbolic_history) symbolic_history.append(extract_symbolic_sequence(stabilized)) extra_attempts = 0 while score < integrity_threshold and extra_attempts < max_extra_candidates: outputs_extra = base_model.generate( **inputs, do_sample=True, max_length=450, num_return_sequences=2, temperature=0.95, top_p=0.95 ) decoded_extra = [tokenizer.decode(o, skip_special_tokens=True) for o in outputs_extra] mutated_extra = [numeric_symbolic_inversion(x) for x in decoded_extra] spiraled_extra = [vector_spiral_transform(x) for x in mutated_extra] stabilized, score = validate_and_select_consistent(reference_seq, spiraled_extra, symbolic_history) extra_attempts += 1 observed = observer.reflect(stabilized) stabilized = recursive_prevention(observed) memory.store(stabilized) attractors.store(stabilized) trace.store(stabilized) state = stabilized match = re.search(r'\[Novelty:(\d\.\d+)\]', observed) current_novelty = float(match.group(1)) if match else 0.0 if current_novelty >= novelty_threshold: break depth += 1 return state # —————————— # Ultra-Long Prompt Generator # —————————— def generate_long_prompt(target_tokens=3500): base_sentence = "The ancient artifact 5E7O1A9Y23 holds secrets unknown. " repeat_count = target_tokens // len(tokenizer(base_sentence)['input_ids']) filler = ''.join(random.choices(string.ascii_letters + ' ', k=500)) return (base_sentence * repeat_count) + filler # —————————— # Benchmark & Visualization # —————————— def benchmark_recursive_ai(prompt, max_depth=8): from copy import deepcopy depth = 0 state = deepcopy(prompt) symbolic_history = [] integrity_scores = [] novelty_scores = [] extra_mutations_used = [] while depth < max_depth: relevant_memory = "\n".join(memory.retrieve(state, top_k=5)) relevant_attractors = "\n".join(attractors.retrieve(state, top_k=3)) relevant_trace = "\n".join(trace.retrieve(state, top_k=5)) working_prompt = f"{state}\nRelevant prior reasoning:\n{relevant_memory}\nConcept attractors:\n{relevant_attractors}\nReasoning Trace:\n{relevant_trace}" inputs = tokenizer(working_prompt, return_tensors="pt", truncation=True).to(device) outputs = base_model.generate( **inputs, do_sample=True, max_length=450, num_return_sequences=4, temperature=0.9, top_p=0.95 ) decoded = [tokenizer.decode(o, skip_special_tokens=True) for o in outputs] mutated = [numeric_symbolic_inversion(x) for x in decoded] spiraled = [vector_spiral_transform(x) for x in mutated] thesis, antithesis = select_divergent_pair(spiraled) emergent = synthesize(thesis, antithesis) reference_seq = extract_symbolic_sequence(mutated[0]) stabilized, score = validate_and_select_consistent(reference_seq, spiraled, symbolic_history) symbolic_history.append(extract_symbolic_sequence(stabilized)) extra_attempts = 0 while score < 0.85 and extra_attempts < 4: outputs_extra = base_model.generate( **inputs, do_sample=True, max_length=450, num_return_sequences=2, temperature=0.95, top_p=0.95 ) decoded_extra = [tokenizer.decode(o, skip_special_tokens=True) for o in outputs_extra] mutated_extra = [numeric_symbolic_inversion(x) for x in decoded_extra] spiraled_extra = [vector_spiral_transform(x) for x in mutated_extra] stabilized, score = validate_and_select_consistent(reference_seq, spiraled_extra, symbolic_history) extra_attempts += 1 observed = observer.reflect(stabilized) stabilized = recursive_prevention(observed) memory.store(stabilized) attractors.store(stabilized) trace.store(stabilized) state = stabilized match = re.search(r'\[Novelty:(\d\.\d+)\]', observed) current_novelty = float(match.group(1)) if match else 0.0 integrity_scores.append(score) novelty_scores.append(current_novelty) extra_mutations_used.append(extra_attempts) if current_novelty >= 0.6: break depth += 1 return { "final_output": state, "integrity_scores": integrity_scores, "novelty_scores": novelty_scores, "extra_mutations": extra_mutations_used } def plot_benchmark(metrics): plt.figure(figsize=(10,5)) plt.plot(metrics['integrity_scores'], label='Symbolic Integrity') plt.plot(metrics['novelty_scores'], label='Novelty') plt.xlabel("Recursion Step") plt.ylabel("Score") plt.title("Recursive AI Benchmark: Integrity vs Novelty") plt.legend() plt.show() print("Extra Adaptive Mutations per step:", metrics['extra_mutations']) # —————————— # Example Full Run # —————————— if __name__ == "__main__": long_prompt = generate_long_prompt(target_tokens=3500) print("Running full prototype on ultra-long prompt (~3.5k tokens)...") start_time = time.time() metrics = benchmark_recursive_ai(long_prompt) end_time = time.time() print(f"\nRun completed in {round(end_time-start_time,2)} seconds.") print("Final Output:\n", metrics['final_output'][:1000], "...\n") # preview first 1k chars plot_benchmark(metrics)



