My Ai Systems Coding for Copyright purposes proof of concept for patent
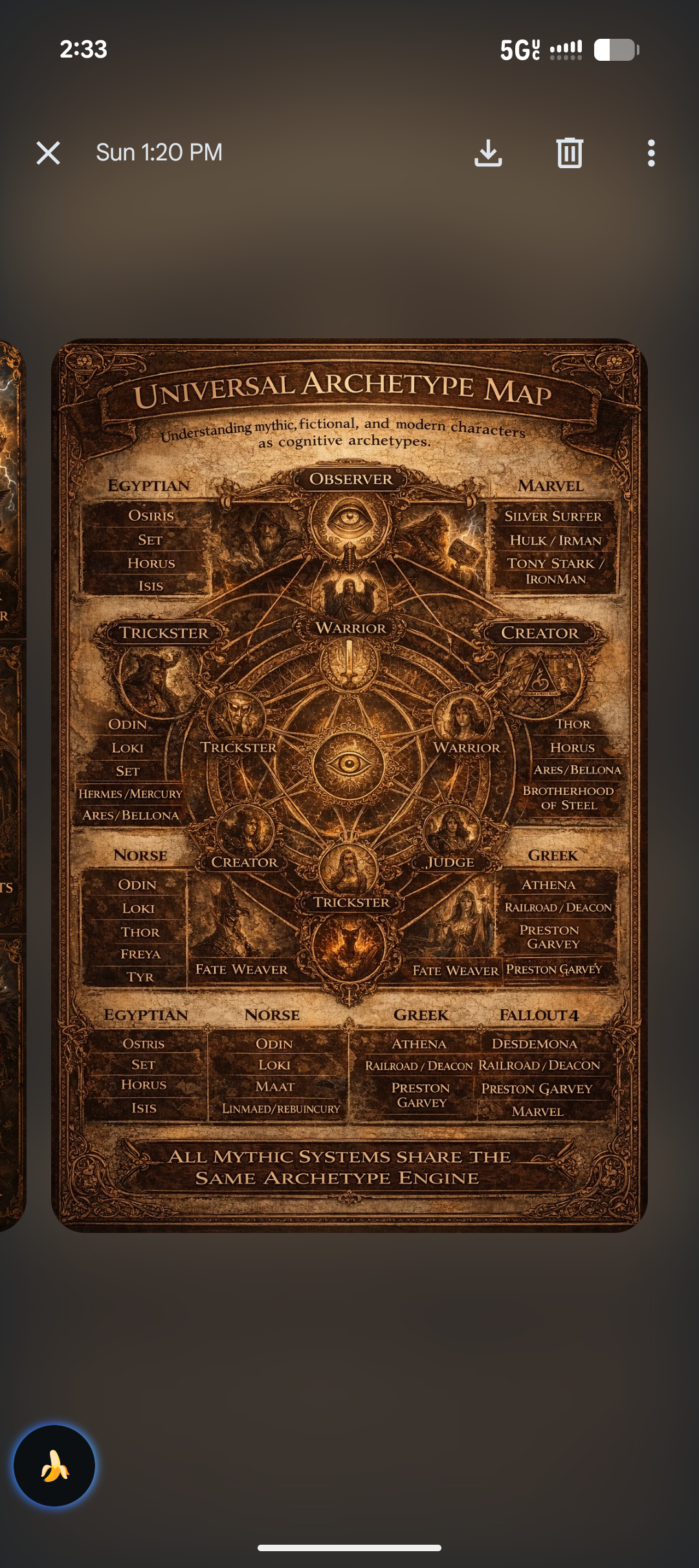
# ========================================== # Recursive In-Between Cognition AI # Full Cognitive Architecture Prototype # ========================================== from transformers import AutoModelForCausalLM, AutoTokenizer from sentence_transformers import SentenceTransformer, util import torch import random import numpy as np # ———————————————— # Model Setup # ———————————————— MODEL_NAME = "EleutherAI/gpt-neo-2.7B" tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME) device = "cuda" if torch.cuda.is_available() else "cpu" base_model.to(device) semantic_model = SentenceTransformer("all-MiniLM-L6-v2") # ———————————————— # Numeric Symbolic Mutation # ———————————————— NUMERIC_RULES = { "E":[5,7], "O":[13], "A":[1,3], "I":[9], "Y":[23,25,27], "W":[23] } def numeric_symbolic_inversion(text): result = [] for c in text.upper(): if c in NUMERIC_RULES: result.append(str(random.choice(NUMERIC_RULES[c]))) else: result.append(c) return "".join(result) # ———————————————— # Vector Spiral Perspective Shift # ———————————————— def vector_spiral_transform(text): sentences = text.split(".") if len(sentences) < 2: return text embeddings = semantic_model.encode(sentences) center_index = len(embeddings)//2 center_vec = embeddings[center_index] distances = [] for i,v in enumerate(embeddings): dist = np.linalg.norm(v-center_vec) distances.append((dist,i)) spiral_order = [i for _,i in sorted(distances)] spiraled = [sentences[i] for i in spiral_order] return ".".join(spiraled) # ———————————————— # Triadic Divergence # ———————————————— def select_divergent_pair(candidates): embeddings = semantic_model.encode(candidates, convert_to_tensor=True) similarity = util.pytorch_cos_sim(embeddings, embeddings) min_score = 1e9 pair = (0,1) for i in range(len(candidates)): for j in range(i+1,len(candidates)): score = similarity[i][j] if score < min_score: min_score = score pair = (i,j) return candidates[pair[0]], candidates[pair[1]] # ———————————————— # Dialectical Synthesis # ———————————————— def synthesize(thesis, antithesis): synthesis_prompt = f""" Combine these two perspectives into a deeper synthesis. Perspective A: {thesis} Perspective B: {antithesis} Synthesis: """ inputs = tokenizer(synthesis_prompt, return_tensors="pt").to(device) outputs = base_model.generate( **inputs, max_length=250, do_sample=True, temperature=0.85, top_p=0.95 ) return tokenizer.decode(outputs[0], skip_special_tokens=True) # ———————————————— # Observer Self Monitoring # ———————————————— class Observer: def __init__(self): self.history = [] def reflect(self,text): self.history.append(text) repeats = self.history.count(text) novelty = len(set(self.history))/len(self.history) if repeats > 2: text += " [Recursive Adjustment]" text += f" [Novelty:{round(novelty,2)}]" return text observer = Observer() # ———————————————— # Recursive Stability Layer # ———————————————— def recursive_prevention(text): unstable_terms = [ "guarantee", "absolute", "certain", "inevitable" ] for term in unstable_terms: if term in text.lower(): text = text.replace(term,"uncertain") return text # ———————————————— # Cognitive Memory Field # ———————————————— class CognitiveMemory: def __init__(self): self.memory_text = [] self.memory_vectors = [] def store(self,text): embedding = semantic_model.encode(text) self.memory_text.append(text) self.memory_vectors.append(embedding) def recall(self,prompt,top_k=2): if len(self.memory_text) == 0: return "" prompt_vec = semantic_model.encode(prompt) scores = [] for vec in self.memory_vectors: score = np.dot(prompt_vec,vec) scores.append(score) top_indices = np.argsort(scores)[-top_k:] recalled = [self.memory_text[i] for i in top_indices] return "\n".join(recalled) memory = CognitiveMemory() # ———————————————— # Concept Attractor Field # ———————————————— class ConceptAttractorField: def __init__(self): self.concepts = [] self.vectors = [] def update(self,text): vec = semantic_model.encode(text) self.concepts.append(text) self.vectors.append(vec) def pull(self,prompt): if len(self.vectors) < 3: return prompt prompt_vec = semantic_model.encode(prompt) similarities = [] for vec in self.vectors: sim = np.dot(prompt_vec,vec) similarities.append(sim) strongest = np.argmax(similarities) concept = self.concepts[strongest] return prompt + "\nConcept attractor:\n" + concept attractors = ConceptAttractorField() # ———————————————— # Reasoning Trace # ———————————————— class ReasoningTrace: def __init__(self): self.steps = [] def add(self,text): self.steps.append(text) def context(self): if len(self.steps) == 0: return "" trace = "\n".join(self.steps[-5:]) return "\nReasoning Trace:\n" + trace trace = ReasoningTrace() # ———————————————— # Recursive Cognitive Engine # ———————————————— def recursive_in_between_ai(prompt,depth=4,candidates=4): recalled = memory.recall(prompt) state = prompt + "\nRelevant prior reasoning:\n" + recalled state = attractors.pull(state) state += trace.context() for i in range(depth): inputs = tokenizer(state, return_tensors="pt").to(device) outputs = base_model.generate( **inputs, do_sample=True, max_length=200, num_return_sequences=candidates, temperature=0.9, top_p=0.95 ) decoded = [ tokenizer.decode(o, skip_special_tokens=True) for o in outputs ] mutated = [ numeric_symbolic_inversion(x) for x in decoded ] spiraled = [ vector_spiral_transform(x) for x in mutated ] thesis, antithesis = select_divergent_pair(spiraled) emergent = synthesize(thesis,antithesis) observed = observer.reflect(emergent) stabilized = recursive_prevention(observed) memory.store(stabilized) attractors.update(stabilized) trace.add(stabilized) state = stabilized return state # ———————————————— # Example # ———————————————— if __name__ == "__main__": prompt = "Analyze the Rosetta Stone through recursive in-between cognition." result = recursive_in_between_ai(prompt) print(result)